BigQuery data compare stored procedure
- timandrews1
- Jul 3, 2022
- 3 min read
At times, you'll find yourself in need of comparing the data within two tables. Often, this comes during times of migrating legacy ETL and data warehouse code to modern equivalents in a cloud data warehouse.
For example, imagine a scenario in which you're migrating fact tables from SSIS and an on-prem SQL Server data warehouse to dbt and Google BigQuery. There is a lot of room for error as not only is the SQL dialect changing, but the logic is shifting from SSIS transformations to a SQL-first scheme within dbt. After converting an SSIS package and fact table to dbt(or stored procedure setup) and Google BigQuery, it can be helpful to validate whether the data in the legacy table matches the data in the new table being fed by ELT into Google BigQuery.
The procedure that I have written below does just that. Assuming that a static copy of the legacy table has been copied into Google BigQuery somewhere, the stored procedure does the following:
Accepts the following input parameters:
source_table (STRING) -- supplied in format dataset.tablename
target_table (STRING) -- supplied in format dataset.tablename
key_col (STRING) -- this is either the name of a column to serve as a comparison key across both tables, or a comma-delimited list of columns for compound keys. Project and/or dataset names are not added.
Queries INFORMATION_SCHEMA to return a list of non-key columns to iterate through and compare between both tables.
Iterates through the list of columns, finding rows in one table but not the other, or rows with different values in equivalent columns when joined across the keys.
Munges the results into summary information.
Creates a table in the source table's schema if not exists and stores the results of the comparison in the table, for future reference.
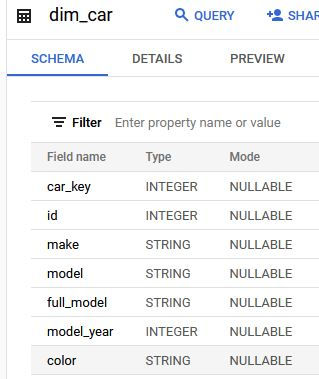
In my example below, I am comparing two tables together - dim_car against dim_car2. This table has a single key column (car_key), along with six attribute columns. Note that there are only around 10,000 rows in each table, so the comparison is fairly quick. For huge tables with hundreds of columns and billions of rows, your mileage may vary, and it might be a better idea to perform more precise comparisons rather than using this sproc as an automated and blunt tool. Regardless, for tables that can handle these automated comparisons, a lot of time is saved by not having to create EXCEPT queries manually, or scripting them out in Excel, etc.
Ahead of time, I changed the value for the "id" column in a row in dim_car2, along with adding a new row to dim_car2 that does not exist in dim_car.
Calling the stored procedure and then querying the results yields the following:
DECLARE my_source_table STRING;
DECLARE my_target_table STRING;
DECLARE my_key_column STRING;
SET my_source_table = 'misc.dim_car';
SET my_target_table = 'misc.dim_car2';
SET my_key_column = 'car_key';
--Perform comparison
CALL misc.p_bq_data_compare(my_source_table, my_target_table, my_key_column);
--Get results from the latest run
SELECT *
FROM misc.bq_data_compare_results
WHERE time_compared = (SELECT MAX(time_compared) FROM misc.bq_data_compare_results);
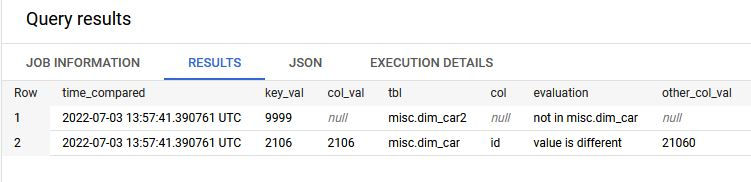
We can quickly see that there is one row (with key_val 9999) that exists in misc.dim_car2, but does not exist in misc.dim_car. Likewise, row with key_val of 2106 does not match in the id column. Both id values are shown for easy diagnosis.
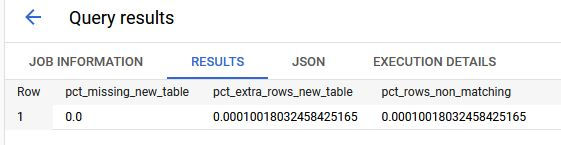
The bq_data_compare_results table can be further summarized to produce metrics that may be relevant to your exercise.
--Get sumary metrics WITH latest_results AS ( SELECT * FROM misc.bq_data_compare_results WHERE time_compared = (SELECT MAX(time_compared) FROM misc.bq_data_compare_results) ) SELECT (SELECT CAST(COUNT(1) AS FLOAT64) FROM latest_results WHERE tbl = my_source_table AND evaluation LIKE 'not in%') / (SELECT COUNT(1) FROM misc.dim_car) pct_missing_new_table , (SELECT CAST(COUNT(1) AS FLOAT64) FROM latest_results WHERE tbl = my_target_table AND evaluation LIKE 'not in%') / (SELECT COUNT(1) FROM misc.dim_car) pct_extra_rows_new_table , (SELECT CAST(COUNT(DISTINCT key_val) AS FLOAT64) FROM latest_results WHERE evaluation NOT LIKE 'not in%') / (SELECT COUNT(1) FROM misc.dim_car) pct_rows_non_matching
Please see complete code on github.
Comments